Service Tomcat Operations Are Being Throttled on Service Discovery Will Try Again Later
Service event messages
When troubleshooting a problem with a service, the first place you should check for diagnostic information is the service event log. You can view service events using the DescribeServices API, the Amazon CLI, or by using the Amazon Web Services Management Console.
When viewing service event messages using the Amazon ECS API, only the events from the service scheduler are returned. These include the most recent task placement and instance health events. However, the Amazon ECS console displays service events from the following sources.
-
Task placement and instance health events from the Amazon ECS service scheduler. These events will have a prefix of service
(service-name). To ensure that this event view is helpful, we only show the100most recent events and duplicate event messages are omitted until either the cause is resolved or six hours passes. If the cause is not resolved within six hours, you will receive another service event message for that cause. -
Service Auto Scaling events. These events will have a prefix of Message. The
10most recent scaling events are shown. These events only occur when a service is configured with an Application Auto Scaling scaling policy.
Use the following steps to view your current service event messages.
- New console
-
-
Open the Amazon ECS console at https://console.amazonaws.cn/ecs/
. -
In the navigation pane, choose Clusters.
-
On the Clusters page, choose the cluster.
-
On the Cluster :
namepage, choose the Services tab. -
Choose the service to inspect.
-
In the Notifications section, view the messages.
-
- Classic console
-
-
Open the Amazon ECS console at https://console.amazonaws.cn/ecs/
. -
On the Clusters page, select the cluster where your stopped task resides.
-
On the Cluster :
clusternamepage, choose Tasks. -
In the Desired task status table header, choose Stopped, and then select the stopped task to inspect. The most recent stopped tasks are listed first.
-
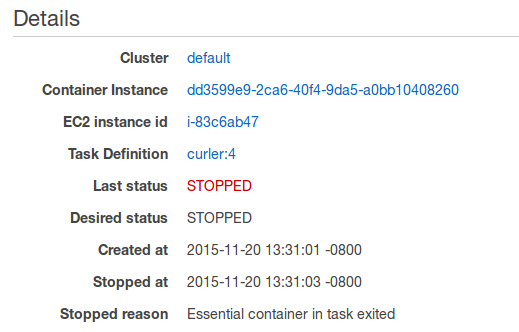
In the Details section, inspect the Stopped reason field to see the reason that the task was stopped.
Some possible reasons and their explanations are listed below:
- Task failed ELB health checks in (elb elb-name)
-
The current task failed the Elastic Load Balancing health check for the load balancer that's associated with the task's service. For more information, see Troubleshooting service load balancers.
- Scaling activity initiated by (deployment deployment-id)
-
When you reduce the desired count of a stable service, some tasks must be stopped to reach the desired number. Tasks that are stopped by downscaling services have this stopped reason.
- Host EC2 (instance
id) stopped/terminated -
If you stop or terminate a container instance with running tasks, then the tasks are given this stopped reason.
- Container instance deregistration forced by user
-
If you force the deregistration of a container instance with running tasks, then the tasks are given this stopped reason.
- Essential container in task exited
-
If a container marked as
essentialin task definitions exits or dies, that can cause a task to stop. When an essential container exiting is the cause of a stopped task, the Step 6 can provide more diagnostic information about why the container stopped.
-
If you have a container that has stopped, expand the container and inspect the Status reason row to see what caused the task state to change.

In the previous example, the container image name can't be found. This can happen if you misspell the image name.
If this inspection doesn't provide enough information, you can connect to the container instance with SSH and inspect the Docker container locally. For more information, see Inspect Docker Containers.
-
- Amazon CLI
-
Use the describe-services command to view the service event messages for a specified service.
The following Amazon CLI example describes the
service-nameservice in thedefaultcluster, which will provide the latest service event messages.aws ecs describe-services \ --clusterdefault\ --servicesservice-name\ --regionus-west-2
Service event messages
The following are examples of service event messages you may see in the Amazon ECS console.
The service scheduler will send a service ( service event when the service is healthy and at the desired number of tasks, thus reaching a steady state.service-name) has reached a steady state.
The service scheduler reports the status periodically, so you might receive this message multiple times.
The service scheduler will send this event message when it could not find the available resources to add another task. The possible causes for this are:
- No container instances were found in your cluster
-
If no container instances are registered in the cluster you attempt to run a task in, you will receive this error. You should add container instances to your cluster. For more information, see Launching an Amazon ECS Linux container instance.
- Not enough ports
-
If your task uses fixed host port mapping (for example, your task uses port 80 on the host for a web server), you must have at least one container instance per task, because only one container can use a single host port at a time. You should add container instances to your cluster or reduce your number of desired tasks.
- Too many ports registered
-
The closest matching container instance for task placement can not exceed the maximum allowed reserved port limit of 100 host ports per container instance. Using dynamic host port mapping may remediate the issue.
- Port already in-use
-
The task definition of this task uses the same port in its port mapping as an task already running on the container instance that was chosen to run on. The service event message would have the chosen container instance ID as part of the message below.
The closest matching container-instance is already using a port required by your task. - Not enough memory
-
If your task definition specifies 1000 MiB of memory, and the container instances in your cluster each have 1024 MiB of memory, you can only run one copy of this task per container instance. You can experiment with less memory in your task definition so that you could launch more than one task per container instance, or launch more container instances into your cluster.
If you are trying to maximize your resource utilization by providing your tasks as much memory as possible for a particular instance type, see Container Instance Memory Management.
- Not enough CPU
-
A container instance has 1,024 CPU units for every CPU core. If your task definition specifies 1,000 CPU units, and the container instances in your cluster each have 1,024 CPU units, you can only run one copy of this task per container instance. You can experiment with fewer CPU units in your task definition so that you could launch more than one task per container instance, or launch more container instances into your cluster.
- Not enough available ENI attachment points
-
Tasks that use the
awsvpcnetwork mode each receive their own elastic network interface (ENI), which is attached to the container instance that hosts it. Amazon EC2 instances have a limit to the number of ENIs that can be attached to them and there are no container instances in the cluster that have ENI capacity available.The ENI limit for individual container instances depends on the following conditions:
-
If you have not opted in to the
awsvpcTrunkingaccount setting, the ENI limit for each container instance depends on the instance type. For more information, see IP Addresses Per Network Interface Per Instance Type in the Amazon EC2 User Guide for Linux Instances. -
If you have opted in to the
awsvpcTrunkingaccount setting but you have not launched new container instances using a supported instance type after opting in, the ENI limit for each container instance will still be at the default value. For more information, see IP Addresses Per Network Interface Per Instance Type in the Amazon EC2 User Guide for Linux Instances. -
If you have opted in to the
awsvpcTrunkingaccount setting and you have launched new container instances using a supported instance type after opting in, additional ENIs are available. For more information, see Supported Amazon EC2 instance types.
For more information about opting in to the
awsvpcTrunkingaccount setting, see Elastic network interface trunking.You can add container instances to your cluster to provide more available network adapters.
-
- Container instance missing required attribute
-
Some task definition parameters require a specific Docker remote API version to be installed on the container instance. Others, such as the logging driver options, require the container instances to register those log drivers with the
ECS_AVAILABLE_LOGGING_DRIVERSagent configuration variable. If your task definition contains a parameter that requires a specific container instance attribute, and you do not have any available container instances that can satisfy this requirement, the task cannot be placed.A common cause of this error is if your service is using tasks that use the
awsvpcnetwork mode and the EC2 launch type and the cluster you specified does not have a container instance registered to it in the same subnet that was specified in theawsvpcConfigurationwhen the service was created.For more information on which attributes are required for specific task definition parameters and agent configuration variables, see Task definition parameters and Amazon ECS container agent configuration.
The closest matching container instance for task placement does not container enough CPU units to meet the requirements in the task definition. Review the CPU requirements in both the task size and container definition parameters of the task definition.
The Amazon ECS container agent on the closest matching container instance for task placement is disconnected. If you can connect to the container instance with SSH, you can examine the agent logs; for more information, see Amazon ECS Container Agent Log. You should also verify that the agent is running on the instance. If you are using the Amazon ECS-optimized AMI, you can try stopping and restarting the agent with the following command.
-
For the Amazon ECS-optimized Amazon Linux 2 AMI
sudo systemctl restart ecs -
For the Amazon ECS-optimized Amazon Linux AMI
sudo stop ecs && sudo start ecs
This service is registered with a load balancer and the load balancer health checks are failing. For more information, see Troubleshooting service load balancers.
This service contains tasks that have failed to start after consecutive attempts. At this point, the service scheduler begins to incrementally increase the time between retries. You should troubleshoot why your tasks are failing to launch. For more information, see Service throttle logic.
After the service is updated, for example with an updated task definition, the service scheduler resumes normal behavior.
This service is unable to launch more tasks due to API throttling limits. Once the service scheduler is able to launch more tasks, it will resume.
To request an API rate limit quota increase, open the Amazon Web Services Support Center
This service is unable to stop or start tasks during a service deployment due to the deployment configuration. The deployment configuration consists of the minimumHealthyPercent and maximumPercent values which are defined when the service is created, but can also be updated on an existing service.
The minimumHealthyPercent represents the lower limit on the number of tasks that should be running for a service during a deployment or when a container instance is draining, as a percent of the desired number of tasks for the service. This value is rounded up. For example if the minimum healthy percent is 50 and the desired task count is four, then the scheduler can stop two existing tasks before starting two new tasks. Likewise, if the minimum healthy percent is 75% and the desired task count is two, then the scheduler can't stop any tasks due to the resulting value also being two.
The maximumPercent represents the upper limit on the number of tasks that should be running for a service during a deployment or when a container instance is draining, as a percent of the desired number of tasks for a service. This value is rounded down. For example if the maximum percent is 200 and the desired task count is four then the scheduler can start four new tasks before stopping four existing tasks. Likewise, if the maximum percent is 125 and the desired task count is three, the scheduler can't start any tasks due to the resulting value also being three.
When setting a minimum healthy percent or a maximum percent, you should ensure that the scheduler can stop or start at least one task when a deployment is triggered.
You can request a quota increase for the resource that caused the error. For more information, see Amazon ECS service quotas. To request a quota increase, see Requesting a quota increase in the Service Quotas User Guide.
The service is unable to start a task due to a subnet being in an unsupported Availability Zone.
For information about the supported Fargate Regions and Availability Zones, see Supported Regions for Amazon ECS on Amazon Fargate.
For information about how to view the subnet Availability Zone, see View your subnet in the Amazon VPC User Guide.
You can request a quota increase for the resource that caused the error. For more information, see Amazon ECS service quotas. To request a quota increase, see Requesting a quota increase in the Service Quotas User Guide.
You can request a quota increase for the resource that caused the error. For more information, see Amazon ECS service quotas. To request a quota increase, see Requesting a quota increase in the Service Quotas User Guide.
Source: https://docs.amazonaws.cn/en_us/AmazonECS/latest/developerguide/service-event-messages.html
0 Response to "Service Tomcat Operations Are Being Throttled on Service Discovery Will Try Again Later"
Post a Comment